
Einleitung
Hochverfügbarkeitsarchitektur und Desaster Recovery sind ein wichtiger Bestandteil jedes kritischen Datenbank- und Anwendungssystems . Im Falle von Ausfallzeiten könnten viele Anwendungen Tausende oder Millionen Von Euro an Umsatz verlieren. Der Sarbanes-Oxley Act von 2002(SOX) regelt interne Kontrollen für Unternehmensinformationen von börsennotierten Unternehmen. Dazu gehört die Notwendigkeit der Systemintegrität und Desaster Recovery-Planung und -Implementierung. Aufgrund der Tatsache, dass eine voll funktionsfähige Desaster Recovery-Site eine hohe Investition in Ausrüstung bietet, ist Linux eine ideale Plattform. Linux bietet sowohl Stabilität als auch Wert.
Die Oracle Maximum Availability Architecture (MAA) ist eine von Oracle entwickelte Blaupause, um sowohl High Availability (HA) als auch Desaster Recovery (DR)-Funktionen für Oracle-Umgebungen bereitzustellen. Die HA-Komponenten bieten Schutz vor dem Verlust einer einzelnen Komponente, während die DR-Komponenten Schutz vor dem Verlust eines kompletten Systems oder dem Verlust eines gesamten Rechenzentrums bieten. Die Maximale Availability-Architektur besteht aus redundanten Komponenten auf allen Ebenen des Anwendungsstapels; Webserver, Anwendungsserver und Datenbankserver . In diesem Blog wird untersucht, wie der MAA als Schutz in einer Reihe von Katastrophenszenarien verwendet werden kann.
HOHE VERFÜGBARKEIT UND DESASTER RECOVERY
High Availability (HA) und Desaster Recovery (DR) sind die Hauptziele der Oracle Maximum Availability Architecture. HA und DR sind ähnlich, da sie beide das Ziel der maximalen Betriebszeit beinhalten, jedoch, HA in der Regel dreht sich um den Verlust eines einzelnen Punkt des Scheiterns zu überleben, während DR beinhaltet die Aufnahme des Betriebs nach dem Verlust eines gesamten Systems oder Rechenzentrums .
HOHE VERFÜGBARKEIT
High Availability oder HA ist eine Entwurfsimplementierung mit dem Ziel, ein System zu erstellen, das nach einem bestimmten Standard (unter normalen Umständen) betriebsbereit ist. Diese Standards werden in der Regel als 9 bezeichnet. Ein System mit einem Betriebszeitbedarf von drei 9ern muss angeblich um 99,9 % der Zeit steigen (Bei 3,6 Tagen Downtime im Jahr). Vier Neunen werden 99,99% der Zeit usw. sein. Der Standard für HA ist in der Regel die Fähigkeit, jedem einzelnen Fehlerpunkt zu widerstehen. Beispielsweise würde das System mit einem RAID-Datenträgersubsystem entworfen werden, das den Verlust eines einzelnen Laufwerks oder einer einzelnen Komponente verarbeiten kann. Die single-point-of- Failure-Kriterien lassen in der Regel nicht mehrere Fehlerpunkte zu. Beispielsweise kann das System den Verlust eines einzelnen Laufwerks verarbeiten, da die Laufwerkspiegelung verwendet wurde. jedoch kann es den Verlust mehrerer Laufwerke gleichzeitig nicht aushalten.
HA-Systeme verwenden redundante Komponenten wie redundanten Speicher, RAID-Festplatten, Netzwerkkarten, um die Möglichkeit zu bieten, einen einzelnen Fehlerpunkt zu überleben. Auf einer höheren Ebene werden redundante Anwendungsserver, Netzwerk Komponenten, und Datenbankserver verwendet, um ein System aus vielen redundanten Komponenten zu erstellen. Ein System kann auch so konzipiert werden, dass es über mehrere redundante Komponenten verfügt. Dies macht es jedoch nicht in der Lage, eine Katastrophe zu überleben, wie z. B. den Verlust des ganzen Rechenzentrums .
DESASTER RECOVERY
Desaster Recovery- oder DR-Systeme sind so konzipiert, dass sie normale Geschäftsfunktionen im Notfall wieder aufnehmen. Es gibt viele Arten von Katastrophen, aber dieses Blog wird sich auf Katastrophen konzentrieren, die das gesamte Rechenzentrum oder das gesamte Datenbanksystem betreffen. Im Rahmen einer dieser Katastrophenarten von Katastrophen wird das Problem nicht gelöst, wenn redundante Komponenten wie RAID-Festplatten vorhanden sind. Es ist wichtig, dass das gesamte Datenbanksystem und die Anwendungsserver redundant sind. Im Notfall wird die Benutzercommunity an das Standby-Rechenzentrum weitergeleitet, um den Betrieb wieder aufzunehmen.
Häufig erfolgt der Umstieg auf das Standby-Rechenzentrum nicht sofort, und einige Daten gehen möglicherweise sogar vorübergehend verloren, je nachdem, wie die Dinge konfiguriert sind. Das Hauptziel der Desaster Recovery-Lösung besteht darin, dass Ihr Unternehmen oder Ihre Organisation im Geschäft bleibt. Kein Unternehmen kann es sich leisten, über einen längeren Zeitraum ausfallen zu können. Für einige Unternehmen jede Stunde, dass das System außer Betrieb ist, kann in Tausende oder Millionen von Euro in verlorenen Einnahmen führen. So ist es wichtig, eine Art DR-System an Ort und Stelle zu haben, auch wenn es mit einer degradierten Leistung läuft. Zumindest hält es das Unternehmen im Geschäft.
ARTEN VON KATASTROPHEN
Es gibt eine Reihe von verschiedenen Arten von Katastrophen, die Sich auf Datenbanksysteme auswirken können. Sie können weit verbreitet oder isoliert sein und einige der folgenden enthalten:
- Systemkatastrophen wie Codefehler, Anwendungsfehler, menschliche Fehler oder Sabotage. Ein Systemverlust aufgrund eines Hardwarefehlers kann auch als Systemnotfall betrachtet werden.
- Natürliche Unruhen wie Hurrikane, Tornados, Überschwemmungen, Erdbeben könnten ein ganzes Gebiet für einen längeren Zeitraum deaktivieren
- Isolierte Katastrophen wie ein Feuer könnten ein ganzes Gebäude für eine erhebliche Zeit deaktivieren
Jede Art von Katastrophe betrifft einzelne oder multiple Komponenten des Systems und muss vor etwas anderen geschützt werden. Einige der Konzepte sind jedoch identisch.
SYSTEM-KATASTROPHEN
Systemkatastrophen können in mancher Hinsicht am einfachsten zu bewältigen sein und in anderen Hinsichten am schwierigsten zu bewältigen sein. Sie können leicht zu bewältigen sein, wenn sie einfach den Verlust einer Komponente oder eines Systems für einen kurzen Zeitraum beinhalten. Diese Art von Katastrophen können gelöst werden, indem das Problem einfach behoben und es wie gewohnt weitergeht. Andere Arten von System desasters können viel schwieriger zu lösen sein, da Sie manchmal nicht einmal erkennen, dass das Problem aufgetreten ist. Ein Benutzer kann z. B. die falschen Daten eingeben und entweder versuchen, sie zu vertuschen, oder sie tage- oder wochenlang nicht erkennen. Es kann sehr schwierig sein, ein Problem zu beheben, das vor Wochen aufgetreten ist, da andere Aktivitäten im System in der Zwischenzeit stattgefunden haben.
Lösung(en): Möglichkeiten zur Vorbereitung und Wiederherstellung nach einem Systemdesaster umfassen gute Backups, die für einen erheblichen Zeitraum aufbewahrt werden, die Verwendung des UNDO-Tablespace, gute Qualitätssicherung und Tests sowie gute Sicherheit.
ISOLIERTE KATASTROPHEN
Bei isolierten Katastrophen geht es um den Verlust eines Computersystems, eines Speichersystems oder sogar des gesamten Rechenzentrums. Dies ist nicht so schlimm wie die Naturkatastrophe, da Sie immer noch Zugriff auf Personal und Ressourcen haben, die lokal zu Ihrem Rechenzentrum sind. Im Falle eines Ausfalls eines einzelnen Systems könnte es möglich sein, entweder den Service fortzusetzen oder ein Ersatzsystem zu verwenden, um relativ schnell wieder in Betrieb zu gehen. Im Falle des Verlusts des gesamten Rechenzentrums muss auf das Standby-Rechenzentrum umgestellt werden.
Lösung(en): Zur Vorbereitung und Wiederherstellung nach einem isolierten Notfall gehören gute Backups, die für eine erhebliche Zeit außerhalb des Standorts aufbewahrt werden, und die Verwendung eines externen Rechenzentrums, das ein lokaler Standort sein könnte.
Naturkatastrophen
Naturkatastrophen verursachen die meisten Zerstörungen, da diese Art von Katastrophe weit verbreitet ist. Das gesamte Rechenzentrum kann für Tage, Wochen oder sogar Monate außer Betrieb sein. Darüber hinaus sind alle Aspekte des Rechenzentrums , einschließlich des Personals , betroffen. Um diese Art von Katastrophe zu überleben, muss das gesamte Rechenzentrum (oder eine Teilmenge) an einem anderen Speicherort reproduziert werden. Darüber hinaus kann es nicht lokal sein, da Naturkatastrophen, wie Überschwemmungen, die gesamte Region betreffen könnten.
Lösung(en): Zum Schutz vor Naturkatastrophen besteht die einzige Lösung darin, ein vollständiges Standby-Rechenzentrum zu entwerfen und zu implementieren. Dieses Standby-Rechenzentrum muss so weit vom primären Rechenzentrum entfernt sein, dass ein weit verbreiteter Ausfall, der durch eine Überschwemmung, ein Erdbeben oder einen Hurrikan verursacht wird, sowohl das primäre als auch das Standby-Rechenzentrum nicht affektiert wird. Neuerdings gibt es dazu Umsetzungen das DR Rechenzentrum in die Cloud zu verlagern, was eine sehr schnelle Redundante Internetanbindung über ein Colt Glasfaser-Netzwerk erfordert.
DIE ORACLE MAXIMUM AVAILABILITY ARCHITECTURE
Die Oracle Maximum Availability Architecture (MAA) ist ein Framework, das sowohl Hochverfügbarkeits- als auch Desaster Recovery-Komponenten für die Fähigkeit mehrerer Notfallszenarien bereitstellt. Oracle MAA umfasst die Erstellung vollständig redundanter Komponenten, einschließlich der Webserver Ebene , der Anwendungs Ebene und der Datenbank Ebene . Es verwendet viele Technologien, einschließlich Oracle RAC und Data Guard, um sowohl HA- als auch DR-Attribute bereitzustellen. Die gesamte MAA ist in der folgenden Abbildung dargestellt:
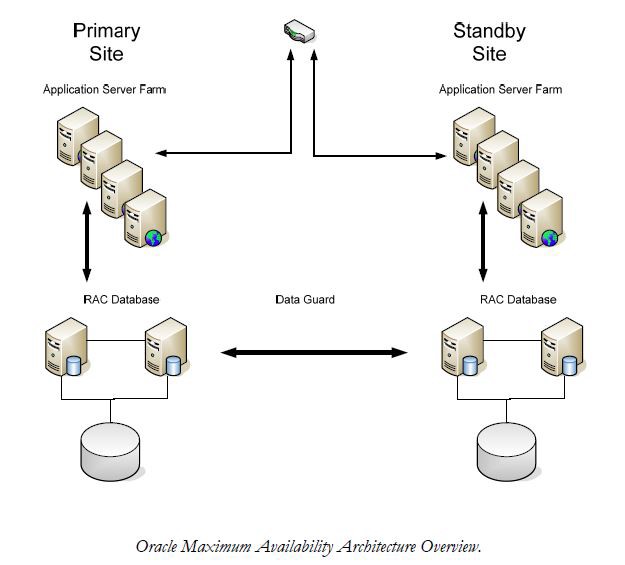
Der MAA besteht aus einer Reihe von Komponenten und Schichten. Durch die Erstellung von vollständiger Redundanz und hoher Verfügbarkeit können sowohl Leistung als auch Schutz beibehalten werden. Wenn sich das Standby-Rechenzentrum weiter vom primären Standort entfernt befindet, bietet sie mehr Schutz vor Naturkatastrophen, jedoch ist das Standby-Rechenzentrum vom Endbenutzer entfernt, desto langsamer wird es sein. So gibt es Kompromisse zwischen Schutz und Leistung zu machen. Aus diesem Grund wurde der MAA entwickelt, um HA-Komponenten sowie DR-Komponenten bereitzustellen. HA übernimmt, wenn es möglich ist, und die DR-Standby-Site ist nur zu verwenden, wenn es unbedingt notwendig ist.
Ob ein vollständiges Standby-Rechenzentrum erstellt wird, das dem primären Rechenzentrum entspricht, oder ob eine kleinere Größe oder Teilmenge erstellt wird, hängt von den Geschäftsanforderungen ab. Wenn die Vereinbarung über den Servicelevel eine Leistungseinbuße für einen bestimmten Zeitraum zulässt, kann es für das Standby-Rechenzentrum akzeptabel sein, weniger Anwendungsserver oder einen kleineren RAC-Cluster oder gar keinen RAC-Cluster zu haben. Dies hängt alles von den Bedürfnissen des Unternehmens und der Service Level Agreement ab.
Wie bereits erwähnt, ist die MAA auf Redundanz ausgelegt. Diese Redundanz muss auf allen Ebenen des Systems vorhanden sein, damit der gesamte Anwendungsstapel im Falle eines Failovers funktioniert. Daher muss der MAA-Entwurf Webserver, Anwendungsservers, Datenbankserver , Speicher- und Netzwerk- und Speicherinfrastruktur umfassen.
ANWENDUNG LAYER REDUNDANCY
Web- und Anwendungs Ebenen sollten mithilfe von HA-Techniken mithilfe mehrerer Server für Web- und Anwendungsdienste konfiguriert werden. Diese Server sind typisch eingerichtet, sowohl mit Lastenausgleich als auch mit Failover. Daher kann der Verlust einer einzelnen Komponente nur zu einer geringen Leistungsminderung führen. Da die Web- und Anwendungsserver den Lastenausgleich unterstützen, besteht ein weiterer Vorteil darin, dass Sie mehr Dienste hinzufügen können, wenn Sie dies benötigen. Linux ist eine ideale Plattform wegen der Leichtigkeit des Kaufs zusätzlicher Hardware und der relativ niedrigen Kosten dieser Hardware.
Um Desaster Recovery zu unterstützen, muss ein Standby-Rechenzentrum verwendet werden und Webserver, Applikationsserver und Datenbankserver enthalten. Darüber hinaus müssen diese Server am Standby-Standort gewartet werden. Die Anwendungen selbst können auf verschiedene Arten gepflegt werden, einschließlich der folgenden:
- Manuelle Synchronisation. Es ist möglich, die Standby-Site manuell zu pflegen. Dies geschieht durch Aktualisieren der Anwendungen sowohl an den primären als auch an den Standby-Standorten, wenn Änderungen vorgenommen werden.
- Betriebssystemreplikation. Es gibt Replikationspakete, in denen Änderungen an OS-Dateien an der Standby-Site repliziert werden. Dies ermöglicht die automatische Synchronisation.
- Speicherreplikation. Viele Speichersysteme unterstützen Optionen, mit denen ganze LUNs vom primären Standort zum Standby-Standort repliziert werden können. Dies ermöglicht eine automatische und kontinuierliche Synchronisation.
In der Regel ändert sich die Anwendungs Ebene nicht dynamisch. Anwendungen werden verwendet, aber nicht ständig geändert; Daher können manchmal einfachere Methoden für die Synchronisation verwendet werden.
Es gibt mehrere Möglichkeiten, die Standby-Anwendungs Ebene zu verwenden. Im Falle des Verlusts der Anwendungs Ebene am primären Standort, an dem die Datenbank Ebene noch funktionsfähig ist, kann die Standby-Anwendungs Ebene an die primäre Datenbank Ebene umgeleitet werden. Dies ist jedoch nicht die Norm. In der Regel ist das Standby-Rechenzentrum ein Alles-oder-Nichts-Design, bei dem der Ausfall einer beliebigen Ebene am primären Standort das gesamte Standby-Rechenzentrum in Betrieb nimmt. Dies ist effizienter , da sich die Webserver Ebene , die Anwendungsserver Ebene und die Datenbank Ebene alle in unmittelbarer Nähe zueinander befinden . Dies ist ein weiterer Grund, warum die MAA auf HA setzt, um Systemprobleme zu behandeln, die lokalisiert sind.
DATENBANK REDUNDANZ MIT RAC
Oracle RAC wird verwendet, um HA auf der Datenbank Ebene bereitzustellen. Oracle RAC verfügt über mehrere Instances, um gleichzeitig auf dieselbe Datenbank zuzugreifen und somit sowohl hohe Verfügbarkeit als auch Skalierbarkeit zu bieten. Oracle RAC gibt es seit vielen Jahren und ist ein stabiles, leistungsstarkes Produkt. RAC kann jedoch nur als HA-Produkt betrachtet werden. RAC bietet keine DR-Funktionen .
INDIVIDUELLE CLUSTERS VS. EINZELCLUSTER MIT MULTIPLE RAC DATENBANKEN
Es gibt mehrere Möglichkeiten, wie ein RAC-Cluster erstellt werden kann, um mehrere Datenbanken zu unterstützen. Eine Methode besteht darin, jede
RAC-Datenbank mit eigener Clusterware und gemeinsam genutztem Speicher. Bei dieser Methode hätte jeder Cluster seine eigene Clusterware, Oracle Cluster Registry (OCR) und Voting Disk. Dies ermöglicht eine vollständige Trennung der Ressourcen, lässt jedoch nicht einfach das Grid-Konzept von RAC zu, bei dem Knoten bei Bedarf einfach hinzugefügt und entfernt werden können. Die zweite Methode besteht darin, eine einzelne Clusterware und ASM zu erstellen, die von allen Knoten verwendet wird, und dann einzeln RAC-Datenbanken innerhalb dieser Infrastruktur zu erstellen. Daher werden alle Knoten als ein einzelner Cluster behandelt, aber Sperren und Datenverkehr für jede RAC-Datenbank werden auf die Knoten beschränkt, auf denen diese Datenbank läuft.
INDIVIDUELLE CLUSTER
Mit den einzelnen Clustern verfügt jede RAC-Datenbank über eine eigene Clusterware und gemeinsam genutzten Speicher für ASM. Dies bietet eine vollständige Trennung von anderen RAC-Knoten, die möglicherweise denselben freigegebenen Speicher verwenden. Diese Trennung bedeutet, dass die Verwaltung, wie z. B. das Patchen in der Datenbank und der Clusterware Oracle Homes, keine Auswirkungen auf andere Systeme hat. Eine Abbildung hier:
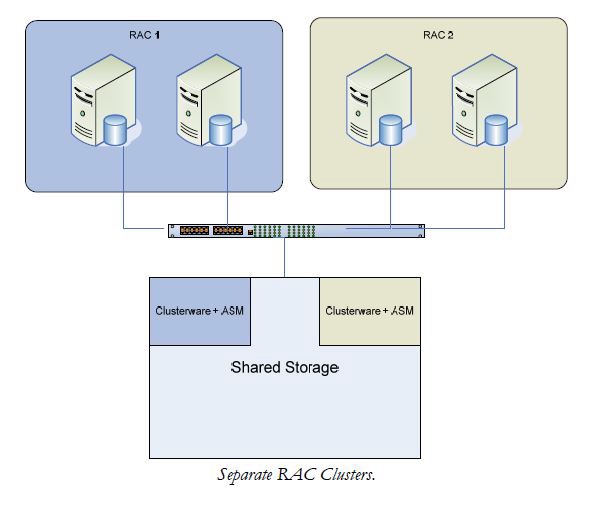
Da Sie mehrere RAC-Datenbanken innerhalb desselben RAC-Clusters haben können, ist es sogar möglich, eine dritte RAC-Datenbank zu haben, die sich über die gesamten vier Knoten des Clusters erstreckt. Mit diesem Modell ermittelt die RAC-Datenbank die Cluster. Dieses Modell bietet maximale Agilität für zukünftiges Wachstum und Modifikation. Es ist einfach, einen vorhandenen Knoten aus einer RAC-Datenbank zu nehmen und ihn der anderen hinzuzufügen oder einfach eine Datenbank auf den anderen Knoten zu erweitern.
Wie bei den meisten Dingen gibt es sowohl Vor- als auch Nachteile für dieses Modell. Der Vorteil besteht darin, dass Knoten jedem RAC-Cluster durch Ausführen von Datenbankbefehlen oder über DBCA zugewiesen werden können. Es ist kein Eingreifen der Systemadministration erforderlich. Es ist auch möglich, ein System Teil von zwei RAC-Datenbanken zu haben, indem RAC 1 auf das System erweitert wird, auf dem RAC 2 läuft. Der Nachteil ist, dass Wartung und Patching auf allen Knoten durchgeführt werden müssen, da die Clusterware- und ASM-Instanz alle der hier gezeigten Systeme umfasst.
Tipp: Erstellen Sie ASM mit einem eigenen Oracle Home. Dies ermöglicht die Wartung der Oracle Homes-Datenbank für das Patchen, ohne ASM herunterziehen zu müssen.
RAC SKALABILITÄT
Die RAC-Skalierbarkeit kann durch unsachgemäßes Anwendungsdesign erheblich beeinträchtigt werden. RAC lässt sich in einer schreibgeschützten Umgebung sehr gut skalieren, und selbst wenn Aktualisierungen, Einfügungen und Löschungen an verschiedenen Teilen der Datenbank durchgeführt werden. Wenn jedoch derselbe Block oder dieselbe Datenzeile von mehreren Knoten im Cluster geändert wird, wird die Skalierbarkeit verringert. Dies ist auf starken Sperren Verkehr und Datenübertragung zwischen Knoten im Cluster zurückzuführen. Wenn ein Knoten im Cluster eine Zeile aktualisieren möchte, die von einem anderen Knoten im Cluster geändert wurde, muss ein ausgeklügelter Sperrmechanismus verwendet werden, um die Sperre für den Knoten aufzuheben, der sie derzeit hält, und dann Sperrinformationen und -daten zu übergeben zum neuen Knoten. Wenn einer dieser beiden Knoten nicht der Blockbesitzer ist, ist auch ein dritter Knoten an diesem Prozess beteiligt.
Daher muss bei einem guten RAC-Anwendungsdesign vermieden werden, dass dieselben Daten von mehreren Knoten geändert werden. Dies kann über die Verwendung von Oracle-Diensten erfolgen. Mit Diensten können Sie bestimmte Benutzer oder Stapeljobs auf bestimmte Knoten verweisen. Falls der gewünschte Knoten nicht verfügbar ist, wird der Standby-Knoten verwendet. Durch Segmentierung der Arbeitslast kann die RAC-Leistung optimiert werden.
DATENBANK REDUNDANZ MIT DATA GUARD
Die Datenbank-DR-Lösung der Wahl ist Oracle Data Guard. Oracle Data Guard verwaltet ein Replikat der Oracle-Datenbank auf einem Standby-Datenbanksystem oder RAC-Cluster . Dieses Standby-System kann im Falle eines Ausfalls des primären Systems verwendet werden. Data Guard kann das Standby-System in einer Reihe von verschiedenen Modi verwalten, basierend auf Ihren Anforderungen und Konfiguration.
DATA GUARD MODES
Data Guard kann so konfiguriert werden, dass er in drei verschiedenen Modi ausgeführt wird. Da eine primäre Datenbank über bis zu 9 sekundäre Server verfügen kann, ist es möglich, zu mischen und abzugleichen (d. h. den maximalen Schutzmodus für lokale Standby-Datenbanken und den Maximum-Performance-Modus für Remote-Standby-Datenbanken zu verwenden). Die Data Guard-Modi sind:
- Maximaler Schutzmodus. In diesem Modus schließt eine Transaktion den Commit-Vorgang erst ab, wenn der Protokolldatensatz sowohl in das primäre Wiederholungsprotokoll als auch in mindestens eine Standby-Wiederholungsprotokolldatei geschrieben wurde. Dies garantiert keinen Datenverlust im Falle eines System Ausfalls. Der maximale Schutzmodus kann jedoch Leistungsprobleme mit der primären Datenbank verursachen, wenn die Verbindung zwischen der primären und der Standby Datenbank nicht schnell genug ist. Wenn die Verbindung zwischen dem primären und dem Standby-System unterbrochen wird, wird das primäre System heruntergefahren, wodurch versichert wird, dass kein Datenverlust möglich ist.
- Maximaler Verfügbarkeitsmodus. Wie im Modus "Maximaler Schutz" schließt eine Transaktion in diesem Modus den Commit-Vorgang erst ab, wenn der Protokolldatensatz sowohl in das primäre Wiederholungsprotokoll als auch in mindestens eine Standby-Wiederholungsprotokolldatei geschrieben wurde. Dies garantiert keinen Datenverlust im Falle eines Systemausfalls. Und wie Der maximale Schutzmodus kann das ganze Leistungsprobleme mit der primären Datenbank verursachen, wenn die Verbindung zwischen den primären und der Standby-Datenbanken nicht schnell genug ist. Der Unterschied zum Modus für maximale Verfügbarkeit besteht darin, dass bei Verlust der Kommunikation zwischen dem primären und dem Standby-System der Kontakt in den Modus "Maximale Leistung" wechselt, bis das Problem behoben ist. Wurde der Link wiederhergestellt, wechselt Data Guard wieder in den Modus Maximale Verfügbarkeit.
- Maximaler Leistungsmodus. Dieser Modus bietet ein Höchstmaß an Schutz, ohne die Leistung der primären Datenbank zu beeinträchtigen. Dies geschieht durch allen fälligen Transaktionen auf dem primären Commit, wenn der Protokolldatensatz in das primäre Wiederholungsprotokoll geschrieben wurde. Der Schreibvorgang in das Standby-Wiederholungsprotokoll erfolgt asynchron. Dies bietet eine bessere Leistung , aber es besteht die Möglichkeit eines Datenverlusts, wenn der primäre Cluster fehlschlägt.
Der gewählte Modus hängt von Ihren spezifischen Anforderungen und Ihrer Konfiguration ab. Da sowohl der maximale Schutzmodus als auch der Modus für maximale Verfügbarkeit erfordern, dass das Standby-Wiederholungsprotokoll geschrieben wird, bevor eine Transaktion als committed betrachtet wird, ist ein schnelles Netzwerk erforderlich. Für jede Millisekunde Verzögerung, die Daten vom primären an sekundäre Standorte sendet, wartet der Commit Vorgang .
BEDENKEN IM DATA GUARD NETWORK
Da das Netzwerk zwischen der primären Datenbank und der Standby Datenbank (n) für die Leistung entscheidend ist, ist es wichtig zu verstehen, welche Auswirkungen diese Leistung hat. Es gibt mehrere Faktoren, die die Leistung zwischen den beiden Standorten beeinträchtigen:
- Entfernung. Es wird oft übersehen, dass Distanz tatsächlich zählt. Es ist möglich, einen Telefonanruf im ganzen Land oder auf der ganzen Welt zu tätigen und es scheint sofort zu sein (obwohl Voice Over IP oder VOIP eine spürbare Verzögerung haben kann). Da das gewählte Signal jedoch physisch auf die Lichtgeschwindigkeit (300.000 Kilometer pro Sekunde) begrenzt ist, würde ein Einwegsignal von NY City nach LA etwa 14,5 ms dauern (vorausgesetzt, es geht von 4345 Kilometern aus ). Ein Signal von NY City nach Denver würde etwa 9,1 ms (unter der Annahme von 2735 Kilometern) und ein Signal von NY bis Philadelphia würde nur 5 ms (vorausgesetzt 143 Kilometern) nehmen. Damit die Übertragung abgeschlossen werden kann, muss sie übertragen, empfangen, in die Standby-Redo-Protokolldatei eingefügt und eine Rücksendebestätigung gesendet werden. Die Entfernung spielt wirklich eine Rolle, und das berücksichtigt nicht einmal Netzwerk Komponenten .
- Netzwerk Komponenten. Jede Firewall, jeder Router und jede andere aktive Netzwerkkomponente fügen Ihrem Signal Verzögerungen hinzu. Je mehr Komponenten zwischen dem primären und dem sekundären Rechenzentrum liegen, desto mehr Latenz wird eingeführt. Zusätzlich zur Entfernungsverzögerung wird also deutlich mehr Zeit für Netzwerk Komponenten verrechnet. Daher ist es in der Regel unpraktisch, dass der maximale Schutzmodus über große Entfernungen verwendet wird.
Bei der Entscheidung, wie Sie Ihre Standby-Site entwerfen, sollten alle Punkte berücksichtigt werden. In der Regel wird ein Maximum Protection Data Guard-System lokal eingerichtet, wobei ein Remotesystem den Maximalen Leistungsmodus verwendet. Dies ist ein guter Kompromiss für den Schutz und die Leistung.
Hinweis: Es gibt mehrere Möglichkeiten, das über ein Netzwerk zu tun. Die Netzwerkpaketgröße kann über Linux optimiert werden, die IP-Framegröße kann mit Jumbo Frames und die Oracle SDU-Größe erhöht werden. Je nach Netzwerk verbessern einige oder alle dieser Informationen die Netzwerkleistung . Es gibt nichts, was getan werden kann, um die Lichtgeschwindigkeit zu erhöhen.
WEITERE WICHTIGE ANLIEGEN
Andere Fragen, die berücksichtigt werden müssen, betrifft die Personalausstattung. Im Falle eines Failovers zum Standby-Rechenzentrum muss Personal vorhanden sein, um diese Systeme zu verwalten. Darüber hinaus muss es Clientsysteme geben, damit DBAs, Systemadministratoren und Mitarbeiter auf die Standby Server zugreifen können. Es muss Platz für die Mitarbeiter und Arbeitsbereiche geben. Dies sollte nicht übersehen werden.
Ein weiteres Problem ist die Benutzergemeinschaft . Bevor Sie ein komplexes DR-System entwerfen, sollten Sie überlegen, wer auf dieses System zugreifen wird. Im Falle des Internet-Geschäfts, wo Benutzer aus der Ferne aus allen Teilen der Welt verbinden, ist die DR-Website absolut kritisch. Wenn Sie für einen längeren Zeitraum nach unten geht, gehen Kunden verloren und Ihr Geschäft könnte kollabieren.
Auf der anderen Seite, wenn Ihr Unternehmen die New Orleans Traffic Division ist, die Internet-Zahlungen für Verkehrsverstöße nimmt , im Gefolge des Hurrikans Katrina ist es unwahrscheinlich, dass jemand bemerken würde, wenn Sie von einem Standby-Standort in Nebraska laufen würden, da die Zahlung einer Verkehrsverletzung zu diesem Zeitpunkt wahrscheinlich keine Priorität hätte. Daher hängt die Notwendigkeit für die DR-Website etwas davon ab, wo sich Ihre Benutzer befinden. In einer weit verbreiteten Katastrophe könnte die Benutzergemeinschaft auch für einen langen Zeitraum außer Betrieb sein.
MAA KEYS ZUM ERFOLG
Um die Oracle Maximum Availability Architecture erfolgreich zu implementieren und zu warten, gibt es mehrere Schlüsselkomponenten . Diese Aufgaben sind Planung, Dokumentation und Ausführung. Wenn eine dieser Komponenten fehlt, ist die MAA gefährdet.
Planung
Es ist wichtig, die MAA gründlich zu planen. Einige der Fragen, die beantwortet werden müssen, sind:
- Was ist das Endziel? Was sind die Betriebsanforderungen ?
- Welche Einrichtungen stehen bereits für ein Standby-Rechenzentrum zur Verfügung? Vorhandene Einrichtungen sind ideal, wenn Sie die richtigen physischen Einrichtungen und das Personal haben.
- Wer wird die Standby-Site betreiben? Im Notfall benötigen Sie lokale Ressourcen, um den Standby-Standort zu verwalten, sobald er primär wird.
Die Antworten auf diese Fragen helfen Ihnen zu bestimmen, wie der MAA zu gestalten ist. Sobald Sie die Lösung geplant und entworfen haben, sollte sie ordnungsgemäß dokumentiert werden.
Dokumentation
Gute Dokumentation ist einer der Schlüssel zum Erfolg. Diese Dokumentation sollte Informationen über die Konfiguration des Systems enthalten, wie man darauf zugreift, wann und wie der Wechsel zum sekundären Standort ausgeführt wird usw. Je mehr Informationen dokumentiert werden, desto erfolgreicher ist die Ausführung . Beachten Sie, dass die Personen, die die Standby-Site entworfen und implementiert haben, möglicherweise nicht verfügbar sind, wenn ein Umschalten erforderlich ist. Daher sollte die Dokumentation detaillierte Anweisungen enthalten, wie sie das Umschalten durchführen, Kontaktinformationen darüber enthalten, wer die Entscheidungsträger sind, und wie Sie die Entscheidung für den Umstieg treffen, falls diese Kontakte nicht verfügbar sind. Darüber hinaus sollten auch Tipps zur Fehlerbehebung bereitgestellt werden. Diese Dokumentation kann die einzige Möglichkeit sein, die den Mitarbeitern des Remote-Rechenzentrums zur Verfügung steht. Machen Sie es so vollständig wie möglich. Stellen Sie außerdem sicher, dass die Dokumentation klar gekennzeichnet ist und an einem Ort(n) gespeichert wird, an dem sie leicht zu finden ist.
Ausführung
Der Erfolg der Ausführung eines Fail-over für das Standby-Rechenzentrum hängt von mehreren Faktoren ab. Dazu gehört die Vollständigkeit der Dokumentation, die Fähigkeiten des Personals und Tests . Die Dokumentation sollte alle Informationen enthalten, die erforderlich sind, um zu entscheiden, ob Sie das standby-Rechenzentrum aktivieren müssen, sowie Anweisungen, wie Sie dies erreichen können.
Das Standby-Rechenzentrum sollte über Mitarbeiter verfügen, die mit Oracle, RAC und Data Guard sowie Systemadministratoren und Netzwerkadministratoren vertraut sind. Dieses Personal muss möglicherweise den gesamten Vorgang über einen längeren Zeitraum ausführen. Schließlich sollten die Tests jährlich durchgeführt werden, wenn ein Praxis-Failover durchgeführt wird. Auf diese Weise können nicht nur die Failover-Mechanismen getestet werden, sondern auch die Qualitätssicherung der Dokumentation. Durch Testen des Failovers können alle Aspekte geübt und die Dokumentation aktualisiert werden, wenn Fehler gefunden werden. Nur durch Tests kann die Gültigkeit des gesamten Systems sichergestellt werden.
Zusammenfassung
Hochverfügbarkeitsarchitektur und Desaster Recovery sind ein wichtiger Bestandteil jeder kritischen Datenbank und Anwendung . Aufgrund der Kosten für die Erstellung eines kompletten Standby-Rechenzentrums ist Linux eine ideale Plattform. Linux ist bekannt für seine Leistung und Stabilität sowie seinen Wert. Durch die Verwendung einer kostengünstigeren Plattform ist es möglich, ein Standby-Rechenzentrum zu erstellen, das das primäre Rechenzentrum genauer repliziert.
In diesem Blog wurden viele Aspekte der Oracle Maximum Availability Architecture und verschiedene Optionen zur Konfiguration von Systemen für hohe Verfügbarkeit und Desaster Recovery erläutert. Wie in diesem Blog erwähnt, ist der Umstieg auf die DR-Site keine einfache Aufgabe, noch ist es notwendigerweise sofort. Daher wird HA benötigt, um lokalen Problemen standzuhalten und maximale Betriebszeiten zu ermöglichen.
Um eine größere Katastrophe zu überleben, ist es notwendig, ein vollständig redundantes Rechenzentrum zu implementieren. Dieses Rechenzentrum kann eine vollständige Kopie des primären Rechenzentrums sein, oder es kann ein verkleinertes Rechenzentrum sein, das genügend Leistung hat, um auf einer beeinträchtigten Leistung ausgeführt zu werden, bis mehr Geräte hinzugefügt werden können oder bis das primäre Rechenzentrum wieder online ist. In jedem Fall ist es wichtig, für den schlimmeren Fall zu planen und bereit zu sein, Ihr Geschäft im Falle einer Katastrophe zu halten. Aus dem aktuellen Standpunkt heraus kann die Cloud helfen ein DR Rechenzentrum mit moderaten Kosten zu betreiben, indem DR Hardware wie eine Exadata Maschine dort gemietet werden kann.