
Ein Fall mit PostgreSQL
Oft kommen Benutzer mit Vorfällen von Datenbankabstürzen aufgrund von OOM Killer zu uns. Der Out Of Memory-Killer beendet PostgreSQL-Prozesse und bleibt der Hauptgrund für die meisten PostgreSQL-Datenbankabstürze, die uns gemeldet wurden. Es kann mehrere Gründe geben, warum einem Hostcomputer der Arbeitsspeicher ausgehen könnte, und die häufigsten Probleme sind:
- Schlecht abgestimmter Speicher auf dem Hostcomputer.
- Ein hoher Wert von work_mem wird global (auf Instanzebene) angegeben. Nutzer unterschätzen oft den Multiplikationseffekt für solche Pauschalentscheidungen.
- Die hohe Anzahl an Verbindungen. Benutzer ignorieren die Tatsache, dass selbst eine nicht aktive Verbindung eine Speicherzuweisung enthalten kann.
- Andere Programme werden gemeinsam auf demselben Computer gehostet und verbrauchen Ressourcen.
Auch wenn wir früher sowohl bei der Optimierung von Host-Maschinen als auch bei Datenbanken geholfen haben, nehmen wir uns nicht immer die Zeit, zu erklären, wie und warum HugePages wichtig sind, und dies mit Daten zu rechtfertigen. Dank wiederholter Sondierung durch einen Freund und Kollegen konnte ich dieses Mal nicht widerstehen.
Das Problem
Lassen Sie mich das Problem mit einem testbaren und wiederholbaren Fall erklären. Dies kann hilfreich sein, wenn jemand den Fall auf seine eigene Weise testen möchte.
Testumfeld
Die Testmaschine ist mit 40 CPU-Kernen (80 vCPUs) und 192 GB installiertem Speicher ausgestattet. Ich möchte diesen Server nicht mit zu vielen Verbindungen überlasten, daher werden nur 80 Verbindungen für den Test verwendet. Ja, nur 80 Verbindungen, die wir in jeder Umgebung erwarten sollten und sehr realistisch sind. Transparent HugePages (THP) ist deaktiviert. Ich möchte das Thema nicht ablenken, indem ich erkläre, warum es keine gute Idee ist, THP für einen Datenbankserver zu haben, aber ich verpflichte mich, dass ich einen weiteren Blog vorbereiten werde.
Um eine relativ persistente Verbindung zu haben, genau wie die von anwendungsseitigen Poolern (oder sogar von externen Verbindungspoolern), wird pgBouncer verwendet, um alle 80 Verbindungen während der Tests persistent zu machen. Im Folgenden wird die pgBouncer-Konfiguration verwendet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[databases] sbtest2 = host=localhost port=5432 dbname=sbtest2
[pgbouncer] listen_port = 6432 listen_addr = * auth_type = md5 auth_file = /etc/pgbouncer/userlist.txt logfile = /tmp/pgbouncer.log pidfile = /tmp/pgbouncer.pid admin_users = postgres default_pool_size=100 min_pool_size=80 server_lifetime=432000 |
Wie wir sehen können, wird der parameter server_lifetime auf einen hohen Wert angegeben, um die Verbindung vom Pooler zu PostgreSQL nicht zu zerstören. Nach PostgreSQL werden Parameteränderungen integriert, um einige der allgemeinen Einstellungen der Kundenumgebung nachzuahmen.
|
1 2 3 4 5 6 7 |
logging_collector = 'on' max_connections = '1000' work_mem = '32MB' checkpoint_timeout = '30min' checkpoint_completion_target = '0.92' shared_buffers = '138GB' shared_preload_libraries = 'pg_stat_statements' |
Die Testlast wird mit sysbench erstellt
|
1 |
sysbench /usr/share/sysbench/oltp_point_select.lua –db-driver=pgsql –pgsql-host=localhost –pgsql-port=6432 –pgsql-db=sbtest2 –pgsql-user=postgres –pgsql-password=vagrant –threads=80 –report-interval=1 –tables=100 –table-size=37000000 prepare |
Und dann
|
1 |
sysbench /usr/share/sysbench/oltp_point_select.lua –db-driver=pgsql –pgsql-host=localhost –pgsql-port=6432 –pgsql-db=sbtest2 –pgsql-user=postgres –pgsql-password=vagrant –threads=80 –report-interval=1 –time=86400 –tables=80 –table-size=37000000 run |
Die erste Vorbereitungsphase belastet den Server mit Schreiblast und die zweite schreibgeschützte Phase.
Ich versuche nicht, die Theorie und Konzepte hinter HugePages zu erklären, sondern konzentriere mich auf die Wirkungsanalyse.
Testbeobachtungen
Während des Tests wurde der Speicherverbrauch mit dem Linux Free Utility-Befehl überprüft. Bei der Nutzung des regulären Pools von Speicherseiten begann der Verbrauch mit einem wirklich niedrigen Wert. Aber es war unter stetigem Anstieg (siehe Screenshot unten). Der "verfügbare" Speicher ist schneller erschöpft.
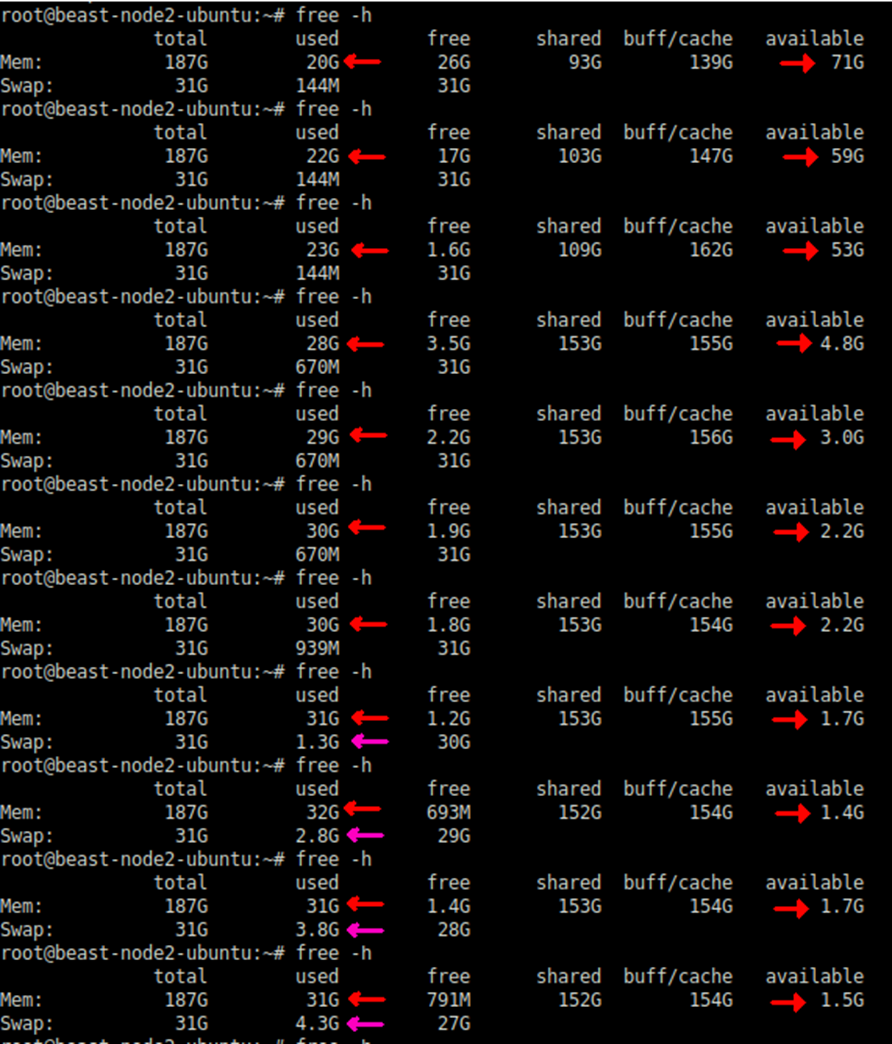
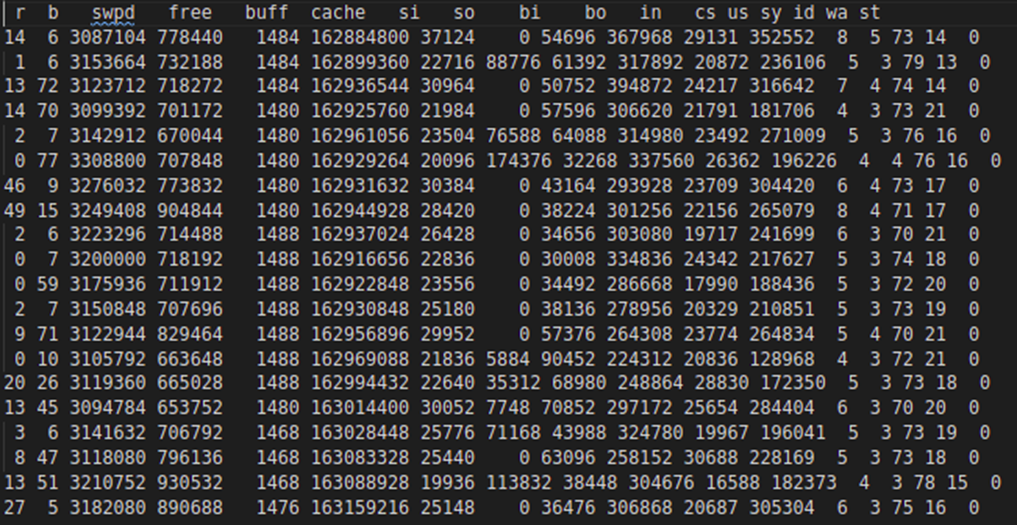
Gegen Ende begann es auch mit swap-Aktivitäten. Die Swap-Aktivität wird in der folgenden vmstat-Ausgabe erfasst:
Informationen aus dem /proc/meminfo zeigen, dass die Gesamtseitentabellengröße von den anfänglichen 45 MB auf mehr als 25 + GB angewachsen ist
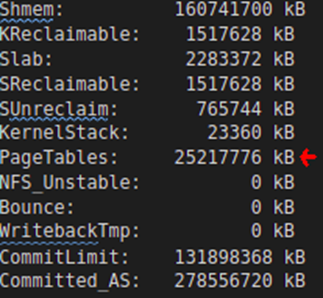
Dies ist nicht nur Gedächtnisverschwendung; Dies ist ein enormer Overhead, der sich auf die Gesamtausführung des Programms und des Betriebssystems auswirkt. Diese Größe ist die Summe der unteren PageTable-Einträge der über 80 PostgreSQL-Prozesse.
Dasselbe kann überprüft werden, indem jeder PostgreSQL-Prozess überprüft wird. Im Folgenden finden Sie ein Beispiel

Die Gesamtgröße der PageTable (25GB) sollte also ungefähr diesen Wert *80 (Verbindungen) haben. Da dieser synthetische Benchmark einen fast ähnlichen Workload durch alle Verbindungen sendet, haben alle einzelnen Prozesse sehr nahe an dem, was oben erfasst wurde.
Die folgende Shell-Zeile kann zur Überprüfung der Pss (Proportional set size) verwendet werden. Da PostgreSQL Linux Shared Memory verwendet, ist es nicht sinnvoll, sich auf Rss zu konzentrieren.
|
1 |
for PID in $(pgrep "postgres|postmaster") ; do awk '/Pss/ {PSS+=$2} END{getline cmd < "/proc/'$PID'/cmdline"; sub("\0", " ", cmd);printf "%.0f –> %s (%s)\n", PSS, cmd, '$PID'}' /proc/$PID/smaps ; done|sort -n |
Ohne Pss-Informationen gibt es keine einfache Methode, um die Speicherverantwortung pro Prozess zu verstehen.
In einem typischen Datenbanksystem, in dem wir eine beträchtliche DML-Last haben, berühren die Hintergrundprozesse von PostgreSQL wie Checkpointer,Background Writer oder Autovaccum-Worker mehr Seiten im gemeinsamen Speicher. Entsprechende Pss sind für diese Prozesse höher.
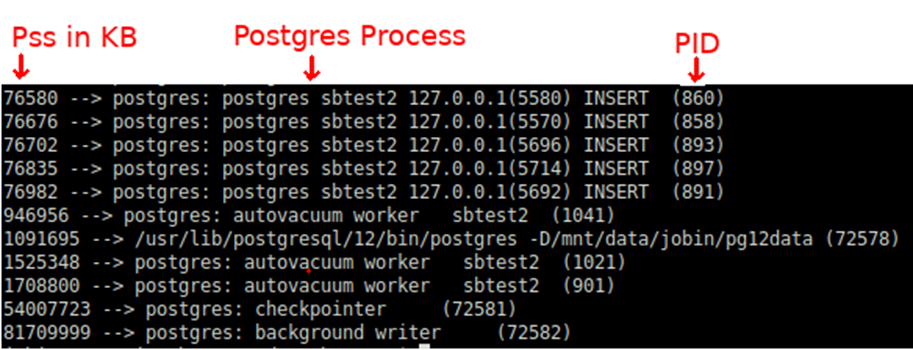
Dies sollte erklären, warum Checkpointer,Background Worker oder sogar der Postmaster oft zum üblichen Opfer/Ziel eines OOM Killers wird. Wie wir oben sehen können, tragen sie die größte Verantwortung für das gemeinsame Gedächtnis.
Nach mehreren Stunden ausführung berührte die einzelne Sitzung mehr Shared Memory-Seiten. Als Konsequenz wurden die Pss-Werte pro Prozess neu angeordnet: Checkpointer ist für weniger verantwortlich, da andere Sitzungen die Verantwortung teilten.
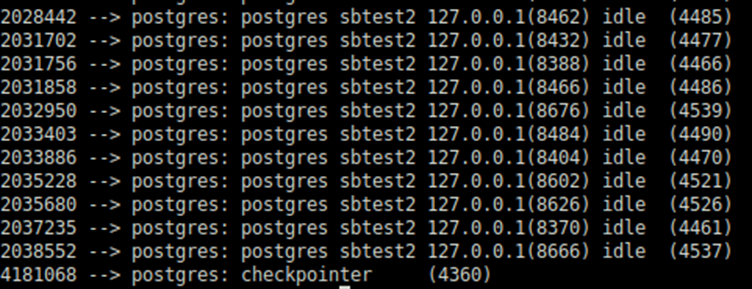
Checkpointer behält jedoch den höchsten Anteil.
Auch wenn es für diesen Test nicht wichtig ist, ist es erwähnenswert, dass diese Art von Lastmuster spezifisch für synthetisches Benchmarking ist, da jede Sitzung so ziemlich die gleiche Arbeit erledigt. Das ist keine gute Annäherung an die typische Anwendungslast, bei der checkpointer und Hintergrundautoren normalerweise die Hauptverantwortung tragen.
Die Lösung: HugePages aktivieren
Die Lösung für solche aufgeblähten Seitentabellen und die damit verbundenen Probleme besteht darin, stattdessen HugePages zu verwenden. Wir können herausfinden, wie viel Speicher HugePages zugewiesen werden sollte, indem wir den VmPeak des Postmaster-Prozesses überprüfen. Wenn beispielsweise 4357 die PID des Postmasters ist:
|
1 |
grep ^VmPeak /proc/4357/status |
Dies gibt die Menge an Speicher an, die in KB benötigt wird:
|
1 |
VmPeak: 148392404 kB |
So viel muss in riesige Seiten passen. Konvertieren dieses Werts in 2 MB Seiten:
|
1 2 3 4 5 |
postgres=# select 148392404/1024/2; ?column? ———- 72457 (1 row) |
Geben Sie diesen Wert in /etc/sysctl.conf für vm.nr_hugepagesan, z. B.:
|
1 |
vm.nr_hugepages = 72457 |
Fahren Sie nun die PostgreSQL-Instanz herunter und führen Sie Folgendes aus:
|
1 |
sysctl -p |
Wir werden überprüfen, ob die angeforderte Anzahl von riesigen Seiten erstellt wird oder nicht:
|
1 2 3 4 5 6 7 |
grep ^Huge /proc/meminfo HugePages_Total: 72457 HugePages_Free: 72457 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 148391936 kB |
Wenn wir PostgreSQL in diesem Stadium starten, könnten wir sehen, dass die HugePages_Rsvd zugewiesen ist.
|
1 2 3 4 5 6 7 |
$ grep ^Huge /proc/meminfo HugePages_Total: 72457 HugePages_Free: 70919 HugePages_Rsvd: 70833 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 148391936 kB |
Wenn alles in Ordnung ist, würde ich lieber sicherstellen, dass PostgreSQL immer HugePagesverwendet, weil ich einen Fehlschlag beim Start von PostgreSQL bevorzugen würde, anstatt später Probleme / Abstürze zu haben.
|
1 |
postgres=# ALTER SYSTEM SET huge_pages = on; |
Die obige Änderung erfordert einen Neustart der PostgreSQL-Instanz.
Tests mit HugePages "ON"
Die HugePages werden bereits vor dem PostgreSQL-Start erstellt. PostgreSQL weist sie einfach zu und verwendet sie. Es wird also nicht einmal eine merkliche Änderung in der freien Ausgabe vor und nach dem Start geben. PostgreSQL weist diesen HugePages seinen gemeinsam genutzten Speicher zu, wenn sie bereits verfügbar sind. Die shared_Puffer von PostgreSQL sind der größte Bewohner dieses gemeinsamen Speichers.
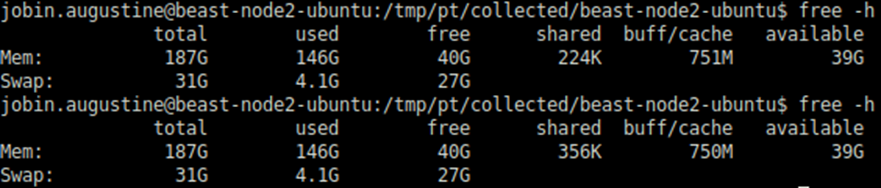
Die erste Ausgabe von free -h im obigen Screenshot wird vor dem PostgreSQL-Start und die zweite nach dem PostgreSQL-Start generiert. Wie wir sehen können, gibt es keine spürbare Veränderung
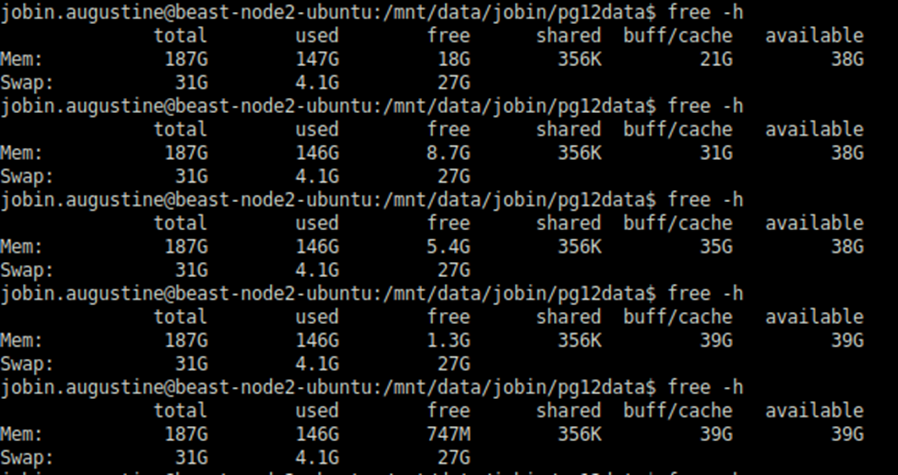
Ich habe den gleichen Test gemacht, der mehrere Stunden lief und es gab keine Änderung; die einzige spürbare Änderung auch nach vielen Stunden der Ausführung ist die Verschiebung von "freiem" Speicher in den Dateisystem-Cache, die erwartet wird und was wir erreichen wollen. Der gesamte "verfügbare" Speicher blieb ziemlich konstant, wie wir im folgenden Screenshot sehen können.
Die Gesamtgröße der Seitentabellen blieb ziemlich gleich:

Wie wir sehen können, ist der Unterschied riesig: Nur 61MB mit HugePages statt bisher 25+GB. Pss pro Sitzung wurde ebenfalls drastisch reduziert:
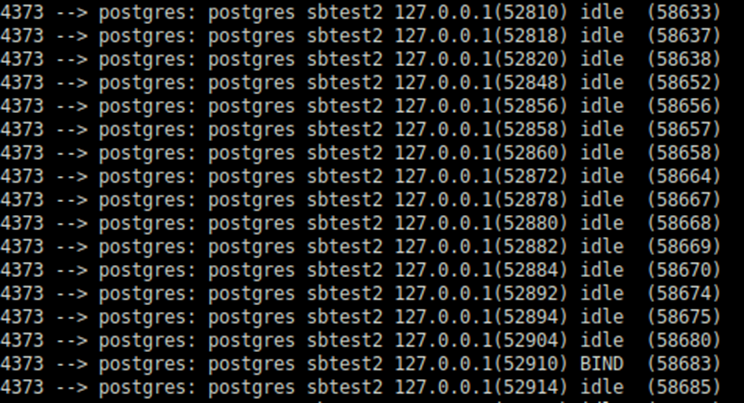
Der größte Vorteil, den ich beobachten konnte, ist, dass CheckPointer oder Background Writer nicht mehr für mehrere GB RAM verantwortlich ist.
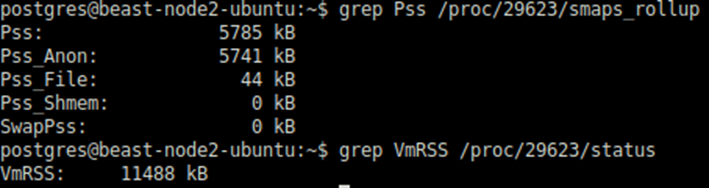
Stattdessen sind sie nur für wenige MBs des Verbrauchs verantwortlich. Offensichtlich werden sie kein Kandidatenopfer mehr für den OOM Killer sein.
Schlussfolgerung
In diesem Blogbeitrag haben wir besprochen, wie Linux Huge Pages den Datenbankserver möglicherweise vor OOM-Killern und den damit verbundenen Abstürzen retten kann. Wir konnten zwei Verbesserungen sehen:
- Der Gesamtspeicherverbrauch konnte deutlich reduziert werden. Ohne die HugePages ging dem Server fast der Speicher aus (der verfügbare Speicher war vollständig erschöpft und die Auslagerungsaktivität wurde gestartet). Nachdem wir jedoch zu HugePages gewechselt hatten, blieben 38-39GB als Available / Linux-Dateisystem-Cache erhalten. Das ist eine enorme Einsparung.
- Wenn HugePages aktiviert ist, werden PostgreSQL-Hintergrundprozesse nicht für eine große Menge an gemeinsam genutztem Speicher berücksichtigt. Sie werden also nicht einfach Kandidatenopfer / Ziel für OOM Killer sein.
Diese Verbesserungen können das System möglicherweise retten, wenn es am Rande der OOM-Bedingung steht, aber ich möchte nicht behaupten, dass dies die Datenbank für immer vor allen OOM-Bedingungen schützt.
HugePage (hugetlbfs) landete ursprünglich im Linux Kernel im Jahr 2002, um die Anforderungen von Datenbanksystemen zu erfüllen, die eine große Menge an Speicher adressieren müssen. Ich konnte sehen, dass die Designziele immer noch gültig sind.
Es gibt weitere zusätzliche indirekte Vorteile der Verwendung von HugePages:
- HugePages werden nie ausgetauscht. Wenn sich freigegebene PostgreSQL-Puffer in HugePages befinden,kann dies zu einer konsistenteren und vorhersagbareren Leistung führen. Ich werde das in einem anderen Artikel diskutieren.
- Linux verwendet eine mehrstufige Seitensup-Methode. HugePages werden mit direkten Zeigern auf Seiten aus der mittleren Schicht implementiert (eine 2 MB große Seite würde direkt auf der PMD-Ebene gefunden werden, ohne dass eine PTE-Seite dazwischen liegt). Die Adressübersetzung wird wesentlich einfacher. Da es sich um einen Hochfrequenzvorgang in einem Datenbankserver mit einer großen Menge an Arbeitsspeicher handelt, werden die Gewinne vervielfacht.
Hinweis: Bei den HugePages, die in diesem Blogbeitrag besprochen werden, handelt es sich um riesige Seiten mit fester Größe (2 MB).
Darüber hinaus möchte ich als Randnotiz erwähnen, dass es im Laufe der Jahre viele Verbesserungen in Transparent HugePages (THP) gibt, die es Anwendungen ermöglichen, HugePages ohne Codeänderung zu verwenden. THP wird oft als Ersatz für reguläre HugePages (hugetlbfs) für eine generische Workload angesehen. Von der Verwendung von THP auf Datenbanksystemen wird jedoch abgeraten, da dies zu Speicherfragmentierung und erhöhten Verzögerungen führen kann. Ich möchte dieses Thema in einem anderen Beitrag behandeln und nur erwähnen, dass dies kein PostgreSQL-spezifisches Problem ist, sondern jedes Datenbanksystem betrifft. Beispiel:
- Oracle empfiehlt, TPH zu deaktivieren. Referenz-Link
- MongoDB empfiehlt, THP zu deaktivieren. Referenz-Link
- "Es ist bekannt, dass THP bei einigen Benutzern unter einigen Linux-Versionen Leistungseinbußen mit PostgreSQL verursacht." Referenzlink.
Da immer mehr Unternehmen eine Migration von Oracle oder die Implementierung neuer Datenbanken neben ihren Anwendungen in Betracht ziehen, ist PostgreSQL oft die beste Option für diejenigen, die auf Open-Source-Datenbanken ausgeführt werden möchten.